
基于用户的协同过滤(Usercf)
- 给用户推荐相似兴趣用户感兴趣的物品(例如开学时候请教实验室的学长学姐)
- 如何评价相似兴趣用户集合(基于用户行为重合度,用户行为重合度越高,相似性就越大)
- 找到集合用户感兴趣的而目标用户没行为过的item
example
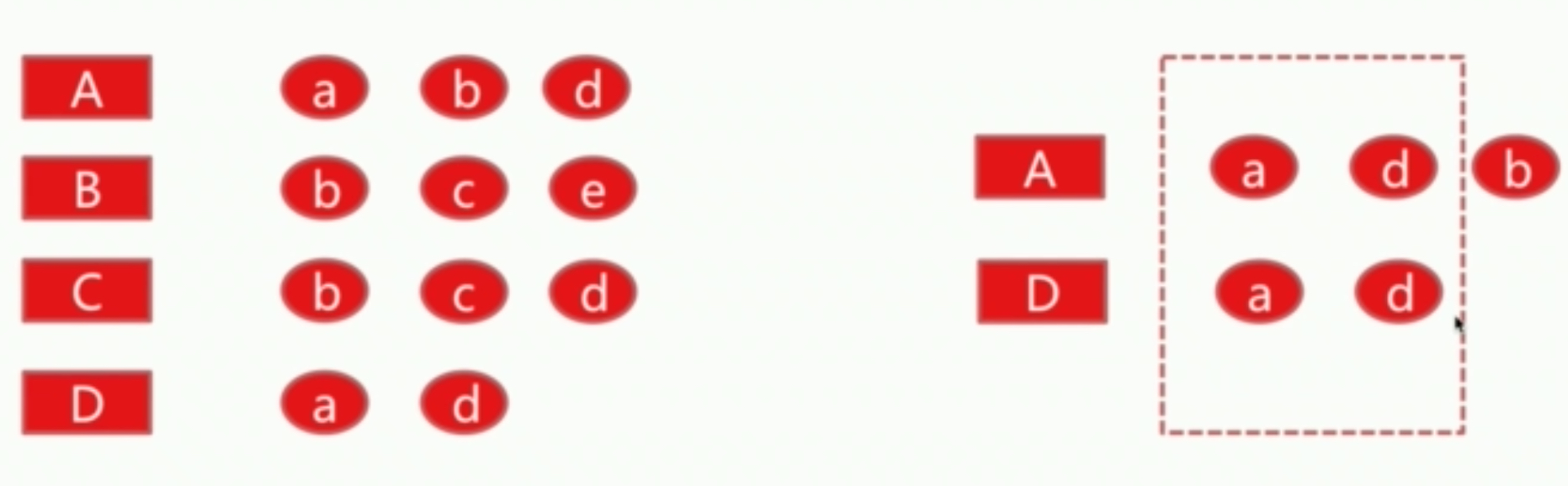
用户A和用户D是相似的,因为它们行为过的物品差不多,因此可以给D推荐他没行为过的物品b。
公式
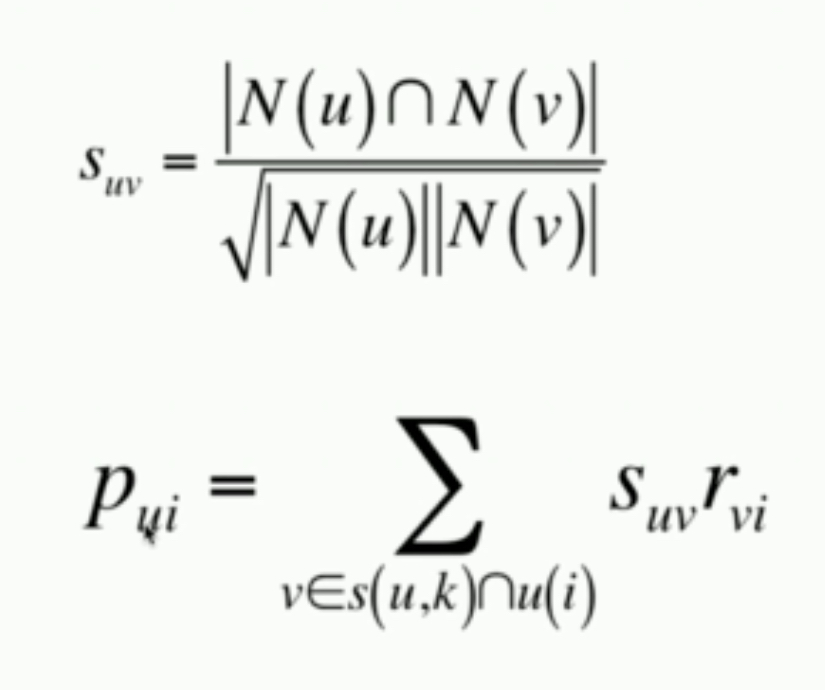
和表示的是用户和用户行为过的物品集合,分母归一化是惩罚那些操作过很多物品的用户,因为他们会使分母过大而无法区分相似度;有了这个公式之后就可以根据用户的行为取推荐物品了;是用户和用户的相似度,则是用户的操作得分,同样要归一化,因为需要关注用户,是和相似的前k个用户,同时与用户行为过相同的物品,这样就可以得到用户对物品的推荐度得分。
公式升级
- 理论意义:降低那些异常活跃物品对与用户相似度的贡献(比如A购买了《新华词典》和《机器学习》,《新华词典》大家都会买,是没办法反映用户兴趣的。)
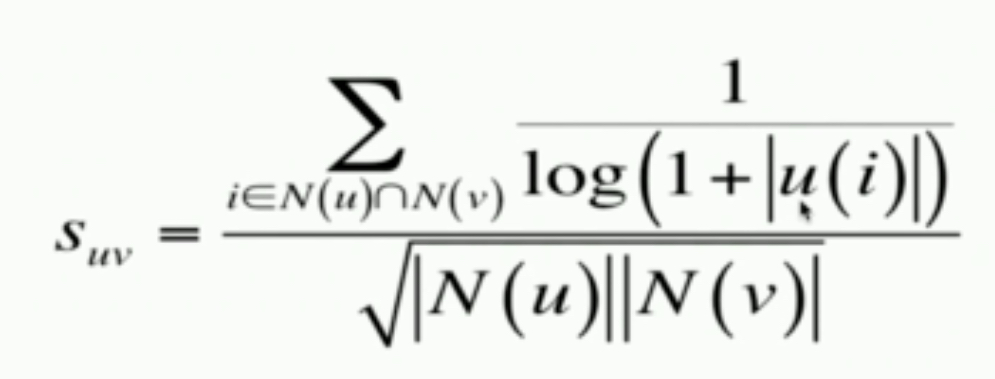
分子的改变反映出的是对用户都作用的物品的影响力削弱。
- 理论意义,不同用户对统一item行为的时间段不同应该给予时间惩罚
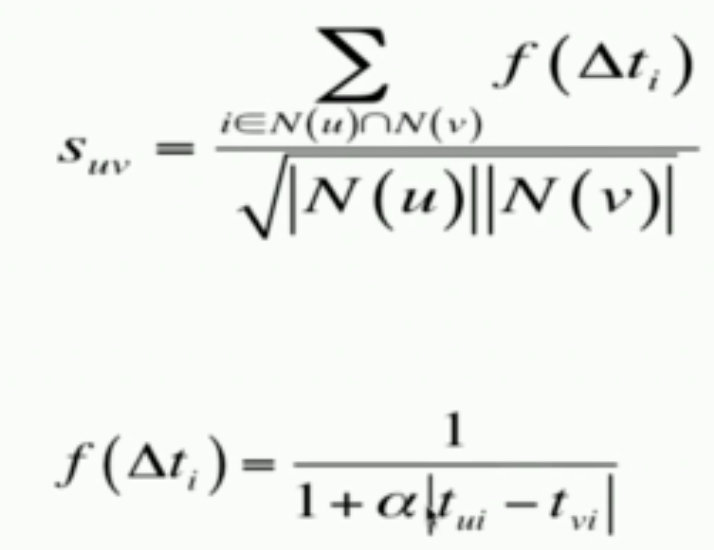
公式中反映出用户对物品作用时间差如果越大,那么这个对用户相似度的影响就越小。